【共學演講】AI批改工作坊:ChatGPT 技術鑑賞
AI 批改工作坊筆記
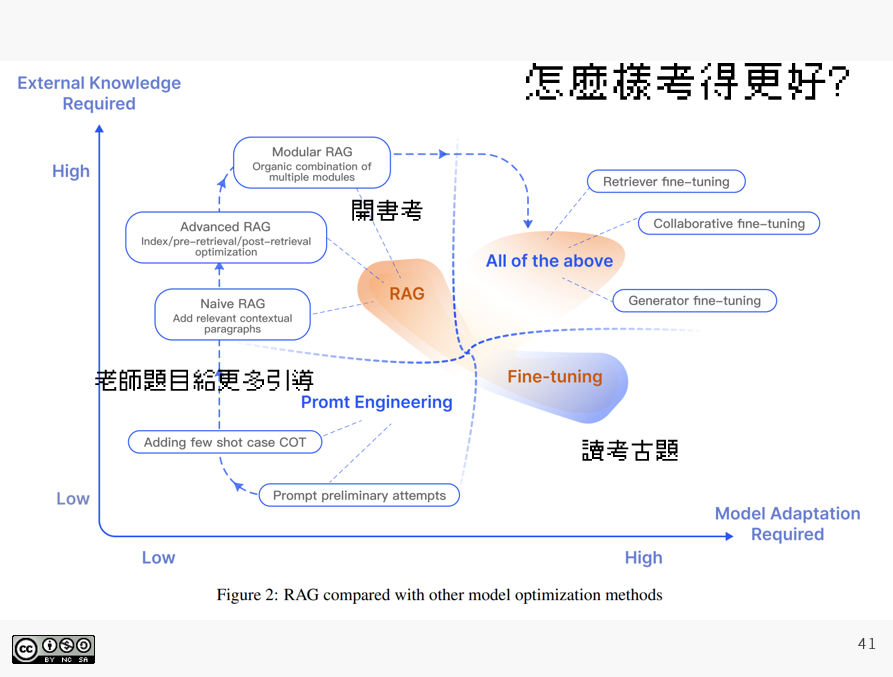
我們在談的 AI 技術是什麼?
本段落難度: ⭐
物格而後知至,知至而後意誠,意誠而後心正,心正而後身修,身修而後家齊,家齊而後國治,國治而後天下平。
總是要先了解這個東西確切是什麼,我們才能正確的態度、方法去創造價值打造應用服務! 順便培養我們在 AI 時代的 AI 素養,以前網路出現的時候我們提倡要有 TPACK ,內容知識(CK)、教學知識(PK)、科技知識(TK),現在我們需要有 AI-PACK。

我們要知道 AI 這個東西是個被濫用的名詞,他指的東西非常的廣泛。當你說 AI 能改作業,就跟我說台灣人能講台語一樣,所以我們要區分一下。
這裡有一些是非題,請你判斷一下,哪個些論述的用詞是正確的,那些是錯誤的?
- 我跟 ChatGPT 聊天,可以透過聊天紀錄來訓練他,讓他產生出我想要的結果。
- ChatGPT 的資料庫裡沒有最新的論文,所以他有時候會傳給我錯誤的引用
- ChatGPT 有記憶,他會記得我的身分跟我最近在做的事


ChatGPT 技術鑑賞
本段落難度: ⭐⭐
這個段落我想透過分解 Open AI 的 ChatGPT 這項產品服務來去向大家介紹現代的 AI 應用服務背後的技術。這裡就把一些常常看到的名詞給一起說文解字一下
看得到的:手機 App、網頁(某個網址)、桌面應用程式、用戶體驗、用戶介面、響應式設計
看不到的:Cookie、API、資料庫、文字模型、思考模型、語音模型、RAG、Prompt、Tools、Agent、訓練、finetune
當我們使用手機 App 或網頁打開 ChatGPT 時,眼前所見的即是一個經過精心設計的用戶介面(User Interface,UI)。透過乾淨、直覺且易於互動的設計,使用者能夠輕鬆理解如何輸入問題、查看答案。而更深入的用戶體驗(User Experience,UX)則不僅僅侷限於外觀,還包含整個互動過程的流暢性與舒適感,例如輸入的反應速度、訊息回應的及時性、回答的準確與實用程度,甚至使用過程中帶來的情感滿足或愉悅感。好的用戶體驗讓使用者願意持續使用該服務,建立起信賴與滿足感。而當你使用不同的裝置去打開 ChatGPT 時,你會發現他們的介面長得不太一樣,那這就是所謂的響應式設計(Responsive Design),確保用戶在手機、平板或電腦等各種不同設備上,都能獲得一致、友好且直覺的互動體驗,避免因為設備不同而產生任何的不便或困擾。
除了看得見的這些介面之外,還有很多看不見的技術在背後運作著。例如,不只有 ChatGPT 很多網頁在使用前都會要你登入或是要求你允許 Cookie,這其實就像是網站給你的一張小小的識別證,它會在你的瀏覽器裡面存放一點點資料,記錄你的登入狀態、設定的喜好,甚至你之前看過的產品或頁面。當你允許 Cookie 的時候,網站就可以透過這些記錄,給你推薦更多你可能會感興趣的廣告或內容,這也就是為什麼當你瀏覽了一些網頁,你在社群平台上的廣告就會改變。當初設計這個技術的開發者把 Cookie 想像成「幸運餅乾」(fortune cookie)裡的小紙條,在這些 Cookie 裡面放著一些簡短的訊息來幫助識別使用者。
網頁版的 ChatGPT 服務,大致可以分成四個部分:Client(用戶端)、Server(伺服器端)、LLM 後端(大型語言模型)和 Database 後端(資料庫)。當你操作 ChatGPT:
→ Client 用戶端,打字輸入問題後按下送出鍵
→ 發送給 Server 端,首先判斷你有沒有登入,你有沒有繳月費,然後進行前處理,包含確認你現在選擇的 Model、你的 System Prompt 、你的聊天歷史紀錄、RAG 相關記憶)
→ 透過 HTTP 請求打 API 叫 LLM 後端回應
→ 以 Streaming 的方式回傳 Server 端, 接收的同時不斷去看看是否要使用工具 Tool (包含 Agent、網路搜尋、再一次發送 API、或開啟虛擬 python 後端…等) (同時進行特殊回應字元篩選)
→ 由 Server 端將回應的資料傳一份給資料庫
→ 由 Server 端將回應的資料傳回給Client 用戶端,顯示在 UI 上
這裡說的 API(應用程式介面,Application Programming Interface)就像是一種「點餐機」,讓不同程式或系統能夠彼此溝通,讓某一系統(客人)可以向另一系統請求資料(點餐),並獲得相應的回覆(拿到餐點),而這個點餐機就像是廚房系統的 API。
你在 ChatGPT 打字輸入問題之後,前端就會去跟 OpenAI 的 API 點餐,把你的問題送出去,後端接到之後,就會透過 LLM 模型去處理,最後再透過 API 將處理好的回覆送回來。因為有這個 API 的設計,前端網頁 (客人) 不用管後端 (廚房) 怎麼運作,只要照 API 的規則來溝通就好。
而 Model 這裡指的是 LLM,GPT 就是其中一類 LLM ,現在的 LLM 有根據輸入輸出的不同模態(文字、圖像、聲音、影片)可以分不同類型。
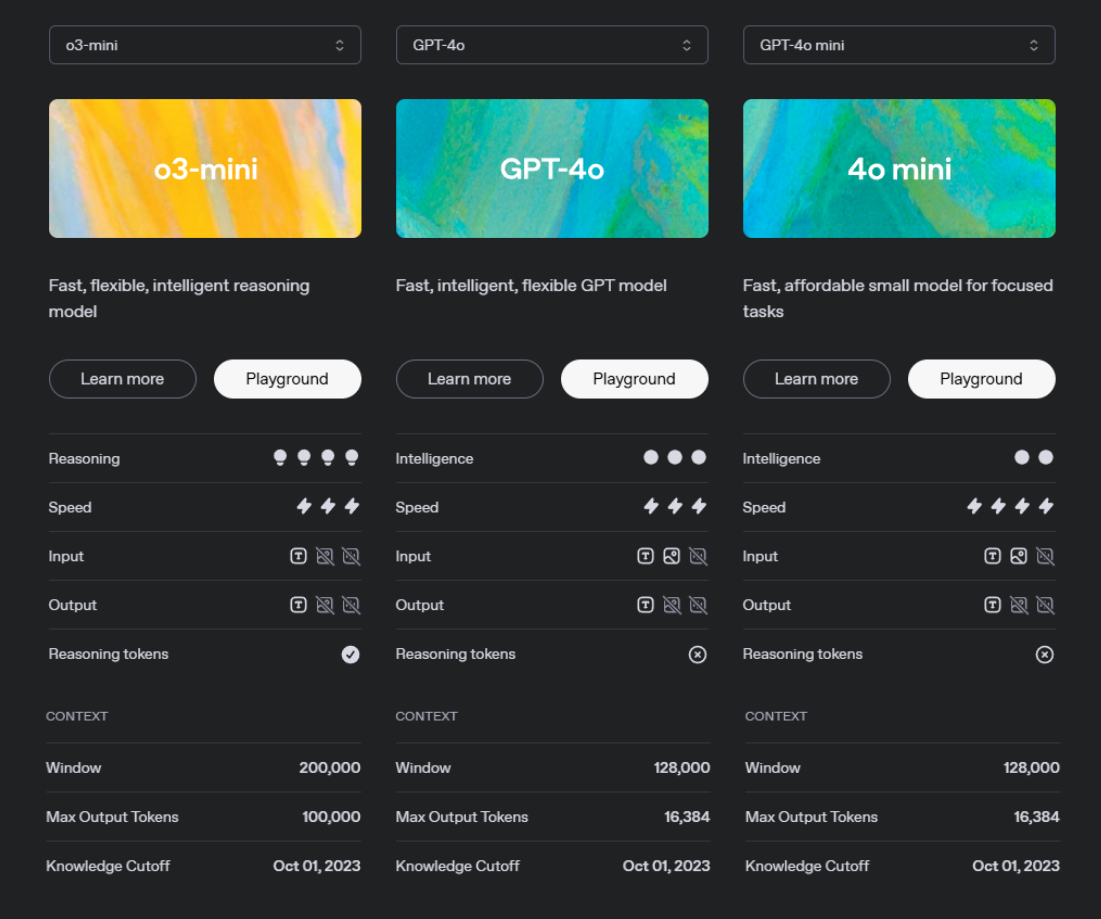
去評鑑一個 LLM 可以看 1. 聰明程度 2. 訓練資料截止日期 3. Context Window
-
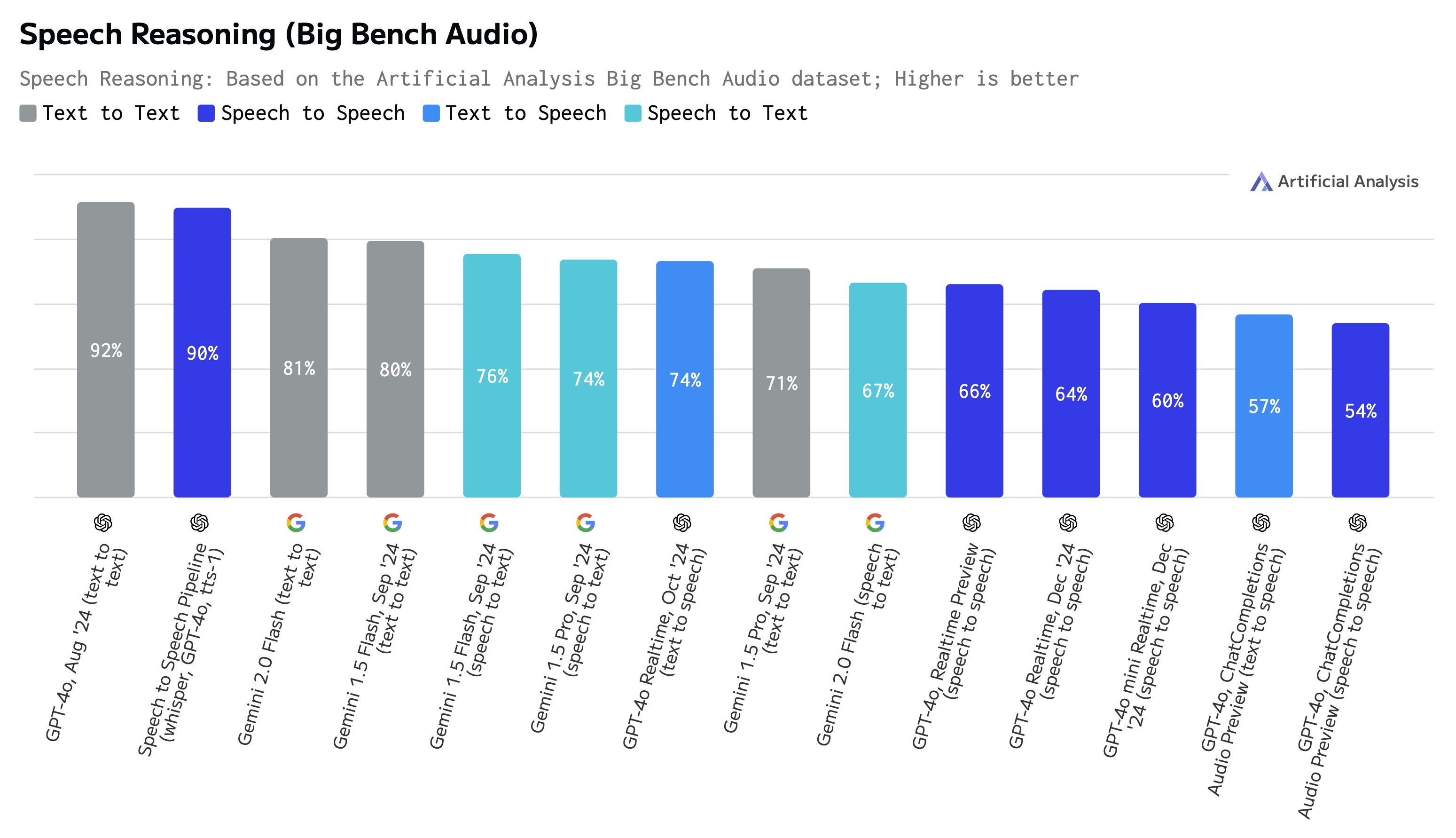
開小窗 1: 多模態的能力會不同(非文字的輸入輸出模型通常表現較弱)


聽力模型也比文字模型還差: 比較好的還是 Pipeline 作法
此外,還可以分普通的 LLM (gpt-4o、gemini-flash) 與會輸出隱藏 CoT Token 的思考模型(Reasoning Model) 像是 OpenAI 的 o1 和 o3 、Deepseek 的 r1 、Google 的 gemini-2.0-flash-thinking、Claude 的 3.7 Sonnet,這種思考模型的 Prompting 技巧比較不同。
-
開小窗 2: 思考模型的比起其他種類的模型在數理問題上表現更好
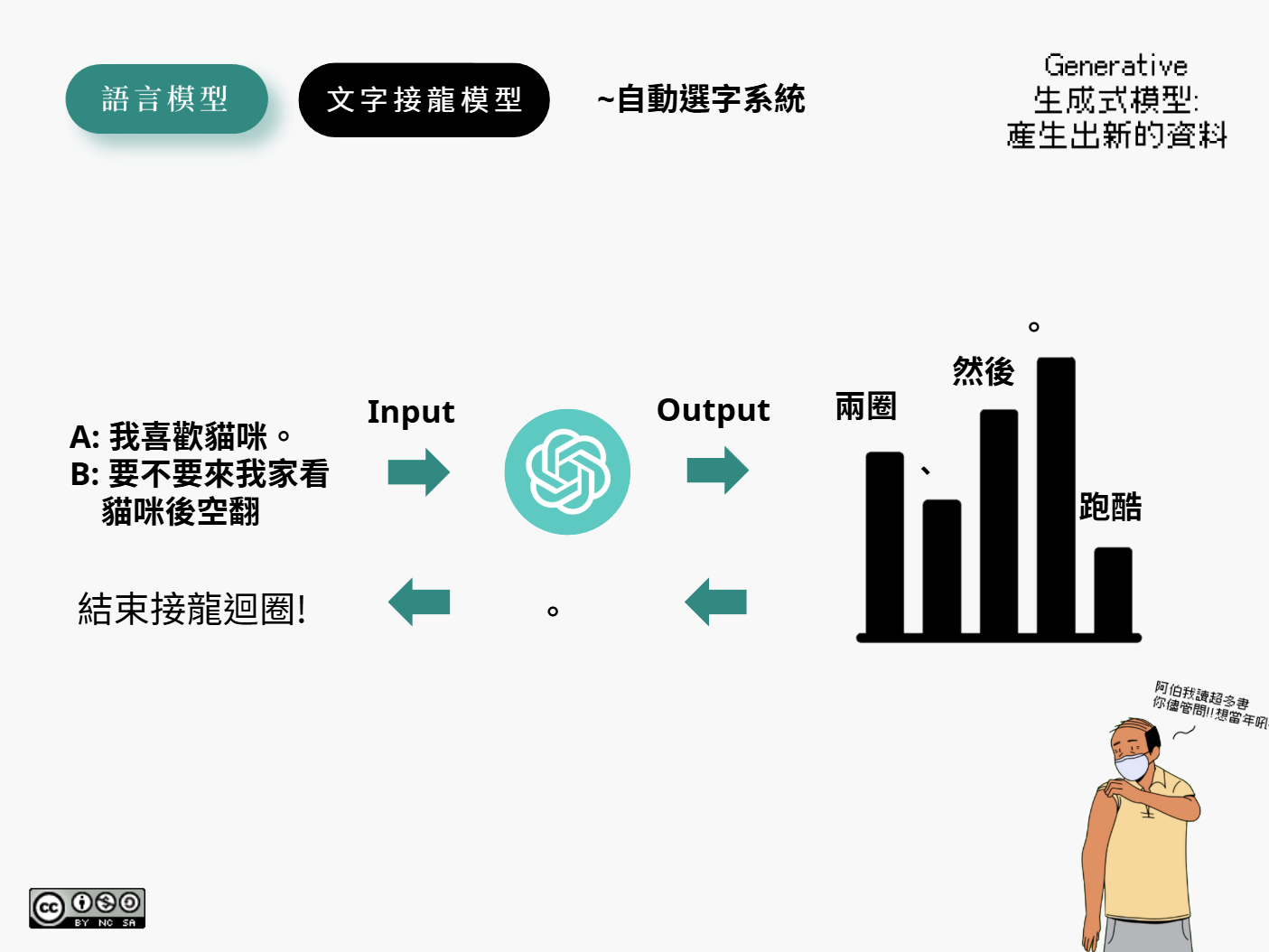
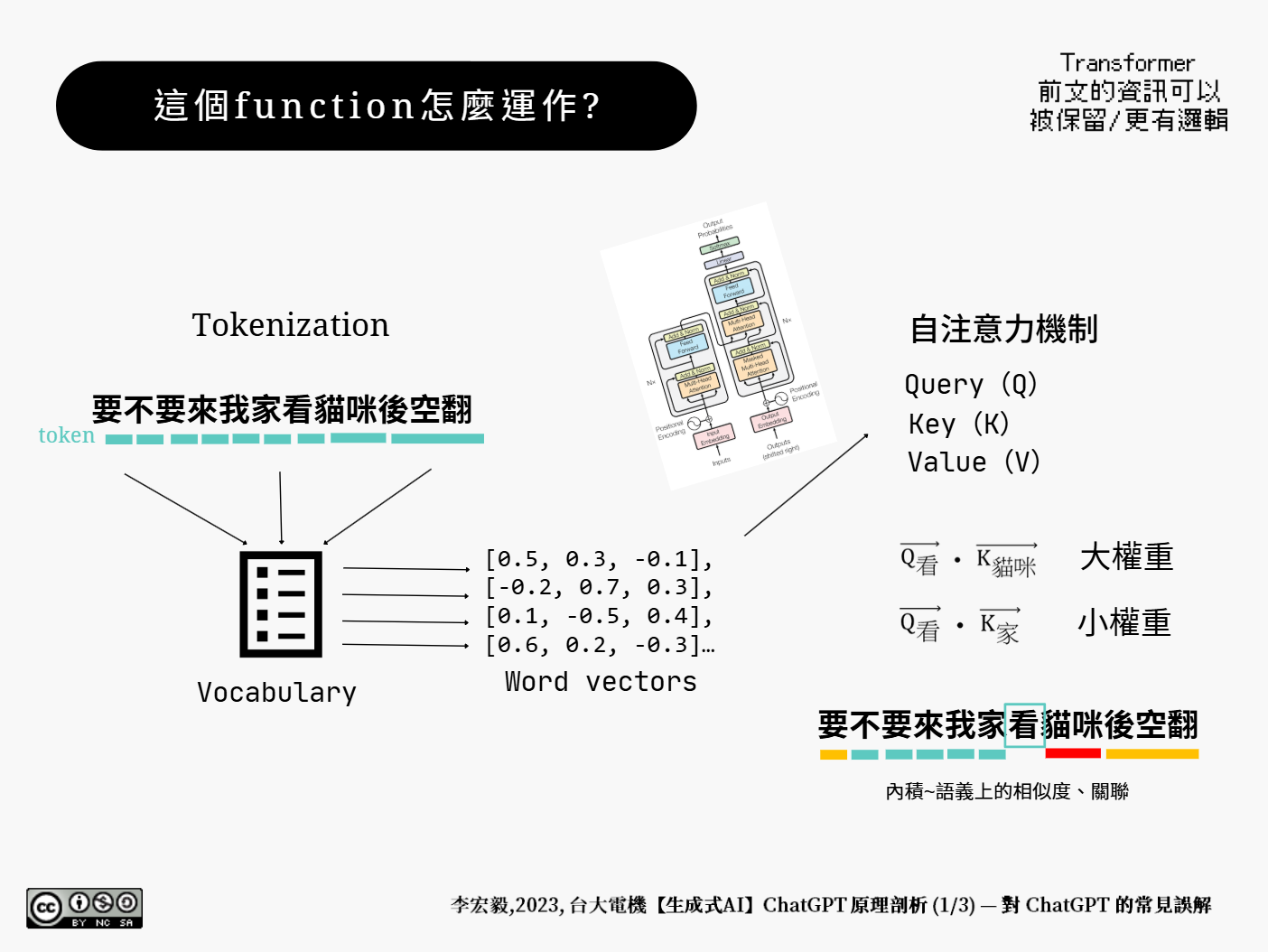
ChatGPT 背後運行的核心技術之一是文字模型(Language Model),例如 GPT(Generative Pre-trained Transformer),該模型經由大量網路文本資料進行訓練,學習並模擬人類語言的結構與使用習慣,以產生符合情境的回覆。而這些訓練資料是有一個截止日期的,如果沒有跟 tool 搭配設計成 agent,它不會知道新聞、不會知道天氣、甚至今天星期幾它都答不出來。
很多人會把 LLM 當作 Google 搜尋來使用,但它的本質不太一樣
以前都會說「 Google 一下就好」,現在都改講「問一下 ChatGPT」
那你說,ㄝ,只是我現在問 ChatGPT 新聞、天氣、日期它都答得出來啊? 那是因為現在的 ChatGPT 不只是單純的 LLM ,工程師訓練 LLM 懂得使用工具,可以讓 LLM 輸出特別的字元以代表在回答中去使用某些特定的工具,包含使用搜尋引擎、開啟虛擬 python 後端、甚至發送指令給其他 LLM,他的流程會是這樣。
""" 使用者: 今天星期幾 ChatGPT:
- 「我要使用 <timetool/> 才能回答使用者訊息」 (生成自 LLM)
- timeTool 回傳 「星期日」
- 包含歷史訊息 + time Tool 的回傳 一起再打一次 API 取得 LLM 回傳
- 「你好今天是星期日」 """
而另一種常見的 tool 是 RAG(Retrieval-Augmented Generation),檢索增強生成技術,在生成回覆前,先從外部或內部的資料庫檢索相關資訊,然後整合這些資訊
資料庫則負責儲存並管理使用者歷史對話紀錄、使用者帳號資訊及偏好設定等結構化資料,以確保數據能快速存取與更新。當使用者再次登入時,透過資料庫可快速調閱歷史記錄,提供連貫且個性化的服務。
回到 AI 批改作業: 從哪裡下手
- 資料預處理: 手寫題 → 數位檔 → 轉文字格式
- Prompt 開發、模型選擇、參數選擇
- 指標: 辨識正確率、價錢、速度
- 文本評量與分析:
- 流程開發、Prompt 開發、模型選擇、參數選擇
- 指標: 信校度、對齊
- 學習回饋與搭配教案:
- 用戶操作與使用者體驗:
本次工作坊挑戰

STEP1 請進去這個我們自己做的網站來挑戰自己能做到最高多少的正確率
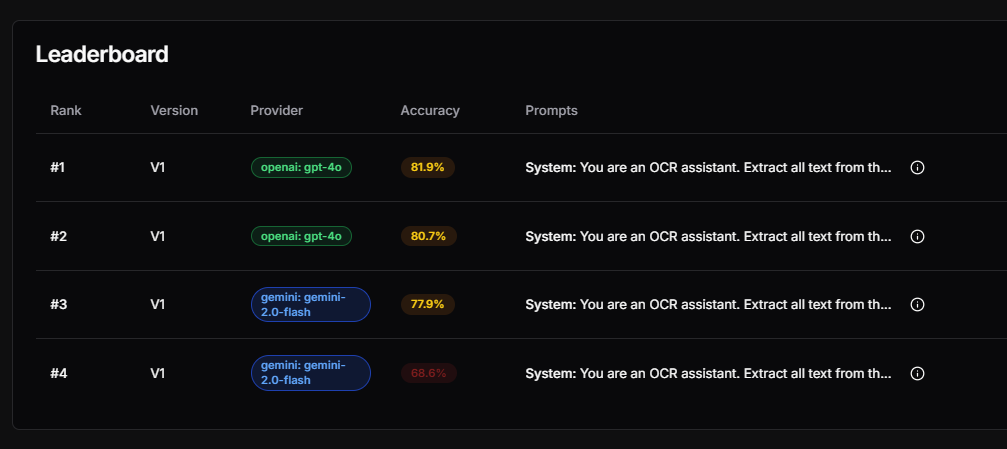
STEP 2 然後將你最好的成果給回報在表單之中! 看誰的正確率能達到最高!
-
範例1: 數學的我自己測 5 個版本,最高搞到 89.4 % 並且感覺已經是堪用的了,錯誤的地方都不是重要的地方
``` You are an OCR assistant. Extract all text from the image accurately. Return only the extracted text without any additional commentary. 請使用Markdown 和 latex 格式來整理你所擷取的內容並且不要使用任何符號包覆回答,數字與單位之間請空格,使用 [、] 和 (、) 包覆 Latex 字元,請格外注意小數點和正負號 ```
-
範例2: 直式作文我最高搞到 71.0 %,我個人覺得我們可以再等等更新的模型,同時建立排行榜網頁,並且 open ai 好像會鎖
``` 你是個專門掃描學生作文的學習幫手,Extract all text from this image accurately. Return only the extracted text without any additional commentary. 你要將以下作文掃描檔內的學生的繁體中文手寫字,一字不漏地按照中文語序(由右至左,由上到下)完整的擷取出繁體中文字來。我只需要作文內文
- 請勿增加或減少圖片內文章裡的任何一個字,務必要完整擷取並保留學生原始寫的所有內容。
- 當你無法辨識某些字時,請由部首去猜測
- 觀察學生的文章,需要按照中文文章慣例來分段(空兩隔分段)。
請仔細的認出作文中的每個字,可以使用上下文去推斷,所有字都是繁體中文。 ```
``` 以下是學生的作文掃描檔 ```
